Claude 的记忆功能:不同的产品哲学
Claude 和 ChatGPT 这两大顶尖 AI 助手,在“记忆”功能的实现上采取了完全相反的两种策略。这种差异深刻地反映了它们各自的产品定位、目标用户群体和设计哲学。
Claude 的记忆系统:显式、可控的工具
Section titled “Claude 的记忆系统:显式、可控的工具”Claude 的记忆功能被设计成一个由用户主动调用的工具,而非一个持续运行的后台服务。其主要特点是:
- 从零开始 (Blank Slate):每次对话都始于一个空白状态,不会预先加载任何用户画像或历史记录。
- 用户主动触发 (Explicit Invocation):记忆功能只有在用户使用“我们上次聊了什么?”等明确指令时才会被激活。
- 基于原始对话的搜索 (Raw History Search):它不会创建 AI 生成的用户摘要或压缩档案,而是通过实时搜索用户的原始聊天记录来回忆信息。
- 两大搜索工具:
conversation_search:根据关键词或主题在全部历史记录中进行搜索。recent_chats:根据时间范围(如“最近10次对话”或“去年11月的最后一周”)来检索对话。
ChatGPT 的记忆系统:隐式、自动的体验
Section titled “ChatGPT 的记忆系统:隐式、自动的体验”与 Claude 相反,ChatGPT 的记忆功能是为大众消费市场设计的,其特点是:
- 自动运行 (Always-On):记忆功能自动加载,无需用户干预,提供即时的个性化体验。
- 创建用户画像 (User Profiling):系统会持续学习用户的偏好和模式,构建详细的用户档案。
- 追求“魔法般”的体验:目标是让产品感觉智能、贴心、无缝,让用户无需思考其工作原理。
哲学与用户的差异
Section titled “哲学与用户的差异”这种设计上的分歧源于两家公司不同的市场策略:
-
Claude 瞄准专业用户:其用户群体主要是开发者、研究人员等技术型专业人士。这些人理解 LLM 的工作原理,偏爱精准的控制权,并能接受为了调用记忆而产生的额外延迟。对他们而言,记忆是一个强大的、可预测的专业工具,隐私和可控性至关重要。
-
ChatGPT 瞄准大众市场:其用户群体覆盖学生、家长等各类普通消费者。他们希望产品开箱即用、简单方便,能自动记住他们的信息。这是典型的消费级科技产品的策略:先通过“魔法般”的体验吸引并留住海量用户,后续再探索商业化模式。
作者认为,两大巨头采取截然相反的路径,说明 AI 记忆功能的设计空间极其广阔,没有唯一的正确答案。最佳方案取决于产品的目标用户和具体需求。目前,这个领域仍处于早期探索阶段(“寒武纪大爆发”),各大公司都在尝试不同的方法,远未形成行业标准。
最后更新:文章发布后不久,Anthropic (Claude 的母公司) 宣布为其团队版和企业版用户推出一项新的记忆功能,该功能看起来更接近 ChatGPT 的自动画像模式。这表明,AI 记忆领域的发展和演变速度极快。
本周早些时候,我剖析了 ChatGPT 的记忆系统。之后我开始对 Claude 进行同样的分析,并发现了一个显著现象:这两个领先的 AI 助手构建了完全相反的记忆系统。
本文将首先详细解析 Claude 记忆功能的工作原理——它存储什么信息以及如何检索信息。然后我们将探讨更有趣的内容:为什么这两种架构会如此迥异,这说明了什么关于各自用户群体和产品开发理念的差异,以及 AI 记忆设计空间究竟有多广阔。
Claude 的记忆系统有两个基本特征。首先,它每次对话都从零开始,不会预加载用户档案或对话历史。只有当你明确调用时,记忆功能才会激活。其次,Claude 通过直接引用原始对话历史来进行回忆。没有 AI 生成的摘要或压缩档案——只是实时搜索你过去的实际聊天记录。
当 Claude 检测到通过"我们讨论过什么"、"继续上次的话题"或"记得我们谈论过"等短语调用记忆时,它会部署两种检索工具,其工作方式类似于网络搜索或代码执行——你可以实时看到它们激活,并在 Claude 搜索历史时等待。搜索完成后,Claude 会综合检索到的对话内容来回答你的问题或继续讨论。
conversation_search 工具帮助在整个对话历史中进行关键词和主题搜索。当我询问"你能回忆我们过去关于月光集市(Chandni Chowk)的对话吗?"(德里的一個历史街区)时,Claude 找到了 9 个相关对话——从我探索其由贾汉娜拉·贝古姆公主于 1650 年建立,到我询问卡里姆餐厅的最佳印度肉丸和帕兰瑟瓦里巷的夹馅烤饼。Claude 将这些分散的讨论综合成了对我月光集市探索的连贯总结。
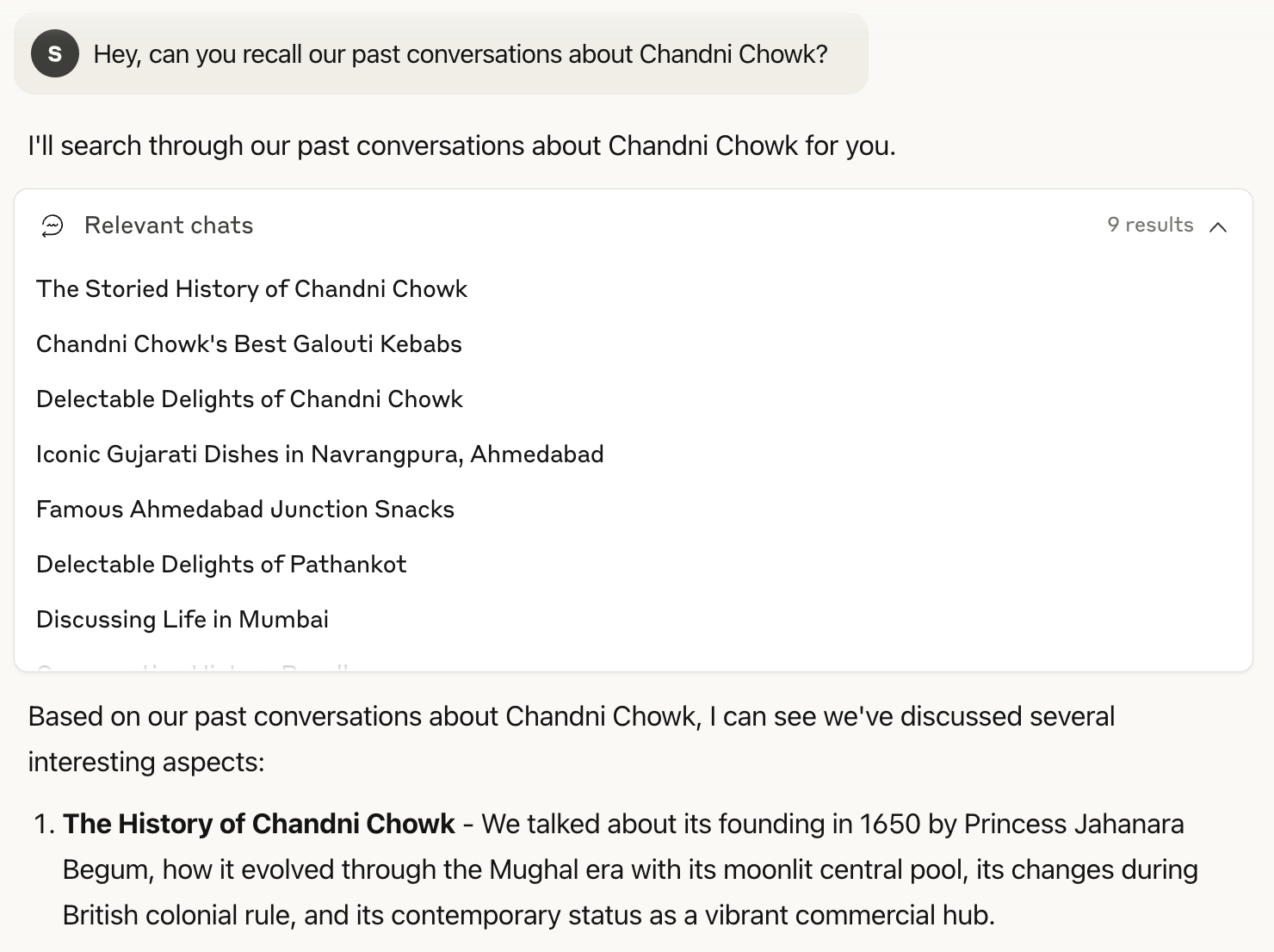
当你询问多个主题时,Claude 会顺序运行单独的搜索。在我过去担任加密研究员的工作中,我广泛使用 Claude 作为编辑工具。当我询问"告诉我们所有关于米开朗基罗或 Chainflip 或 Solana 的对话"时,Claude 运行了三个独立的搜索——一个针对我对神经网络使用的米开朗基罗类比,另一个关于 Chainflip 的跨链协议工作,第三个关于 Solana 的技术架构。它通过这些搜索找到了 22 个对话,并提供了包含每个聊天直接链接的统一回复。

conversation_search 工具定义
{ "description": "搜索过去的用户对话以查找相关上下文和信息", "name": "conversation_search", "parameters": { "properties": { "max_results": { "default": 5, "description": "要返回的结果数量,介于 1-10 之间", "exclusiveMinimum": 0, "maximum": 10, "title": "最大结果数", "type": "integer" }, "query": { "description": "用于搜索的关键词", "title": "查询", "type": "string" } }, "required": ["query"], "title": "对话搜索输入", "type": "object" }}时间对话检索
Section titled “时间对话检索”recent_chats 工具提供基于时间的对话历史访问。当我询问"你能告诉我们最近 10 次对话的内容吗?"时,Claude 按时间顺序检索了我最近的聊天记录,并给了我最近使用情况的摘要。
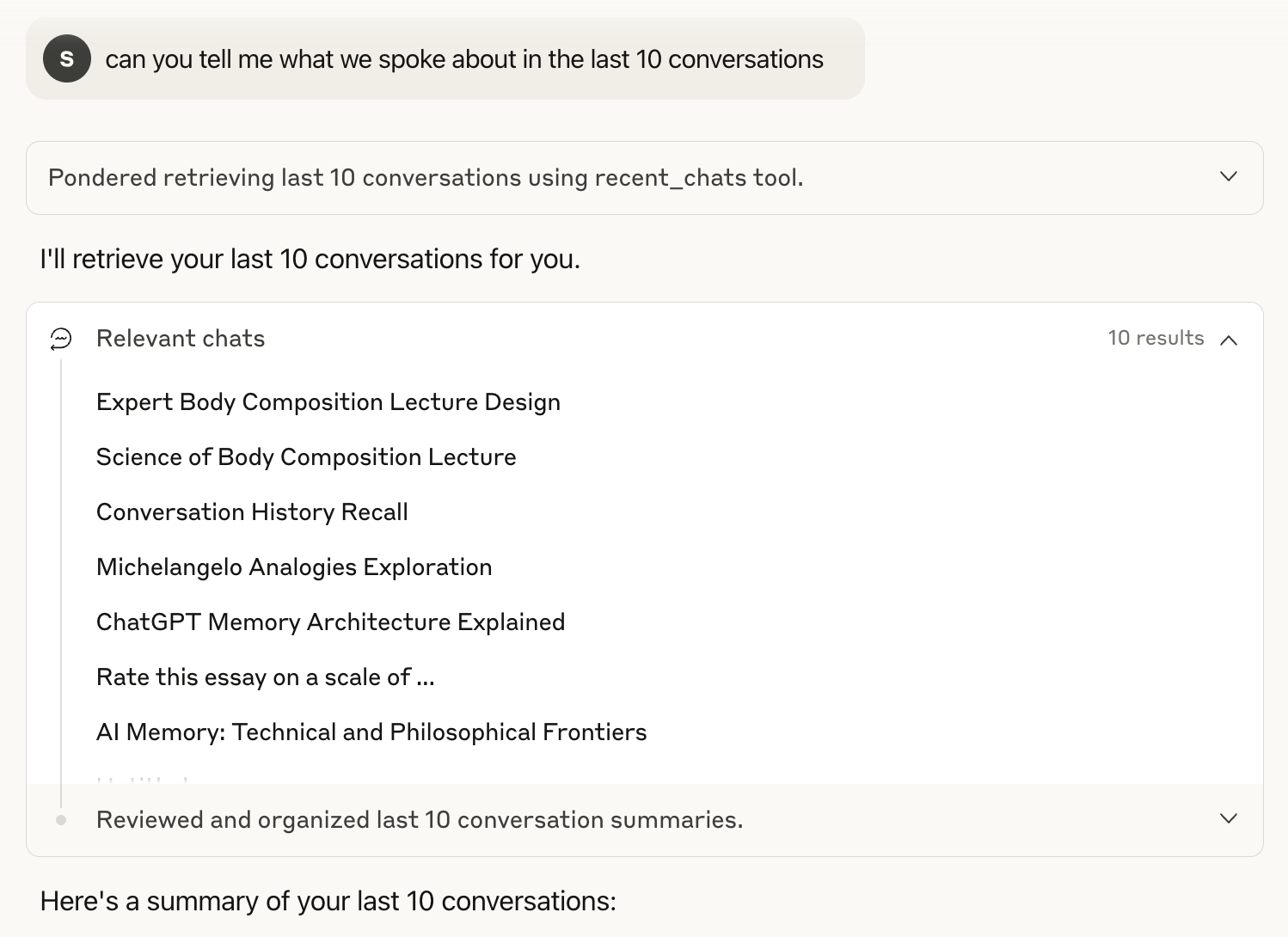
该工具还处理特定时间范围。当我询问"我们在 2024 年 11 月最后一周讨论了什么?"时,Claude 检索了该确切时期的 16 个对话。

recent_chats 工具定义
{ "description": "检索最近的聊天对话,具有可定制的排序顺序(按时间顺序或倒序)、使用‘before’和‘after’日期时间过滤器的可选分页功能,以及项目过滤", "name": "recent_chats", "parameters": { "properties": { "after": { "anyOf": [{"format": "date-time", "type": "string"}, {"type": "null"}], "default": null, "description": "返回在此日期时间之后更新的聊天(ISO 格式,用于基于游标的分页)", "title": "之后" }, "before": { "anyOf": [{"format": "date-time", "type": "string"}, {"type": "null"}], "default": null, "description": "返回在此日期时间之前更新的聊天(ISO 格式,用于基于游标的分页)", "title": "之前" }, "n": { "default": 3, "description": "要返回的最近聊天数量,介于 1-20 之间", "exclusiveMinimum": 0, "maximum": 20, "title": "数量", "type": "integer" }, "sort_order": { "default": "desc", "description": "结果排序顺序:'asc' 表示按时间顺序,'desc' 表示倒序(默认)", "pattern": "^(asc|desc)$", "title": "排序顺序", "type": "string" } }, "title": "获取最近聊天输入", "type": "object" }}ChatGPT 与 Claude 对比
Section titled “ChatGPT 与 Claude 对比”一年前,ChatGPT 和 Claude 的助手应用在功能上不相上下——多种模型、文件附件、项目功能。但从那时起,它们的路径出现了显著分歧。ChatGPT 已经演变为一个大众市场消费产品,而 Claude 则刻意选择了不同的发展轨迹。Anthropic 首席产品官 Mike Krieger 已经承认,OpenAI 在消费者采用方面"抓住了闪电"。Anthropic 没有追逐那个市场,而是专注于 Claude 最擅长的领域:开发者工具、编程和专业工作流程。
记忆功能的实现完美反映了这种分歧。
ChatGPT 的数亿周活跃用户来自各种背景——学生、家长、爱好者——他们只想要一个能正常工作并能记住他们的产品,而不需要考虑技术细节。每个记忆组件都会自动加载,实现零等待时间的即时个性化。系统构建详细的用户档案,学习偏好和模式,最终可能用于支持定向功能或货币化。这是典型的消费科技策略:让它神奇,让它粘性,以后再想办法货币化。
Claude 的用户代表了完全不同的群体。Anthropic 的技术型用户天生理解大语言模型的工作原理。他们习惯于在各个层面进行显式控制。就像他们选择何时触发网络搜索或启用扩展思考一样,他们决定何时值得调用记忆功能。他们理解记忆调用会增加延迟,但他们会刻意做出这种权衡。记忆成为他们武器库中的又一个工具,而不是一个常开功能。这个受众不需要也不想要广泛的画像分析——他们需要一个强大、可预测的专业工作工具。更不用说,他们也更加注重隐私。
记忆设计空间
Section titled “记忆设计空间”ChatGPT 和 Claude——这两个顶级 AI 助手——构建了完全相反的记忆系统,这仍然让我感到惊讶。这只能说明 AI 中的记忆功能拥有巨大的设计空间,没有正确答案或一刀切的技术。你必须从你的用户是谁和他们需要什么出发,然后相应地基于第一原则进行构建。
我们处于未知领域。这些工具出现还不到三年,没有人知道当某人使用同一个 AI 助手十年会发生什么。它应该记住多少?它应该如何处理多年积累的上下文?与此同时,我们正在见证 AI 应用的寒武纪大爆发,每个应用都在试验自己的记忆方法,而底层模型每周都变得更强大。没有剧本,没有既定的最佳实践——只是每个人都在尝试不同的事情,看看什么有效。
我越深入研究记忆功能,就越着迷。在接下来的几周里,我将剖析不同的架构,分析新的方法,并跟踪最新的研究。如果你想在这个领域发展时获得更新,请在下方订阅。
更新: 发布本文几小时后,Anthropic 宣布为团队和企业账户推出新的记忆功能,看起来更接近 ChatGPT 的方法。尚未尝试(Max 计划不可用),但一旦尝试后会分享更新。 喜欢这篇文章吗?订阅以获取新帖子。